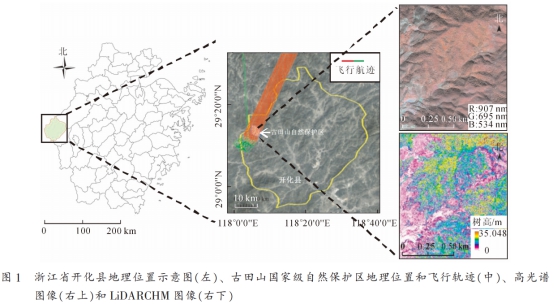
如何利用高光譜和機載激光雷達進行樹種的識別?
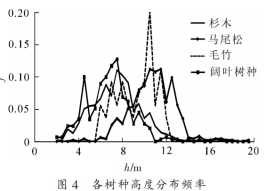
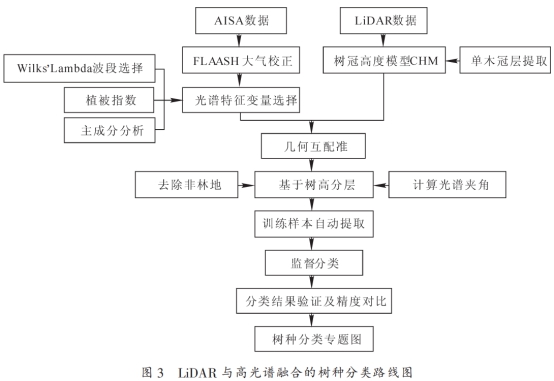
訓練樣本的選取是影響監督分類精度的直接原因之一,數據空間分辨率越高,訓練樣本要求越準確,而人機交互訓練樣本選取推廣力有限。利用機載高光譜(AISA)和激光雷達(LiDAR)主被動遙感數據,探討基于高分辨率影像的訓練樣本自動提取技術以及適合樹種識別的遙感變量。根據樹木的結構和高度差異,開展樹高分層掩膜試驗,并計算光譜間夾角,在每個高度層中自動化優選樹種的高純度訓練樣本。計算植被指數、主成分分析等特征變量,基于支持向量機分類器對研究區進行樹種精細分類。實驗表明:通過對闊葉林、馬尾松Pinus massoniana,毛竹Phyllostachys edulis,杉木Cunninghamia lanceolata,油茶Camellia oleifera的訓練樣本分層自動提取后再進行分類,激光雷達和不敏感色素指數變量能有效提高樹種分類精度。其中高光譜+激光雷達+結構不敏感色素指數變量組合的分類精度最高,其總體精度和Kappa系數分別為89.12%和0.86,闊葉林、馬尾松、毛竹、杉木、油茶的用戶精度分別為75.00%,100.00%,86.36%,90.91%和96.55%。該方法對本研究區森林樹種的識別是有效的。
Ø 結論與討論
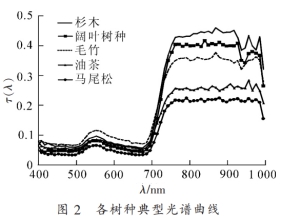
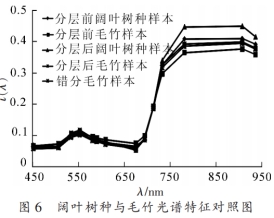
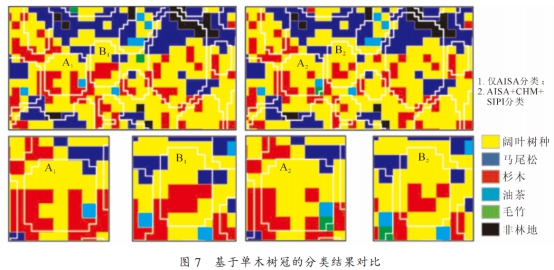
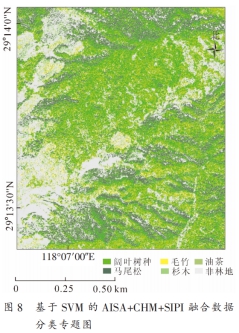
高光譜是光學被動遙感數據,其窄波段特性在較小的空間尺度上能區分地表細微變化,在樹種識別方面有顯著優勢。但由于 “同物 異譜、 異 物 同 譜” 現 象 的 存在, 導致分類精度受限。 機載 LiDAR 是主動遙感數據,可獲得樹種垂直結構及強度信息, 與高光譜優勢互補,有效解決不同高度下不同地物因具有相似光譜特征而導致的混分問題。 采用分層訓練樣本自動提取技術, 不僅提高了訓練樣本選取的速度還有效提高訓練樣本選取精度, 更從一定程度上盡可能地避免混分現象。本研究結合 高光譜與機 載 LiDAR 的數據優 勢, 為評估 LiDAR 垂直結構信息與特征變量參與分類的貢獻,比較了基于 AISA, CHM, SIPI 和 PCA1 這 4 種不同變量組合的分類精度。 其中 AISA+CHM+SIPI 變量組合的分類精度最高, 其總體精度 和 Kappa 系數分 別為 89.12%和 0.86, 比僅 AISA 分類的總體精度高 23.81%, 比 AISA+CHM 高 12.25%, 比 AISA+SIPI 高 11.57%。 但結果同時表明, PCA 降維變量的分類貢獻要明顯弱于 SIPI。 本研究區為典型的亞熱帶森林, 其中闊葉林內樹種種類繁多, 與其他類型的樹種混雜生長, 所以純林區較少, 易產生混合像元。 在 AISA+CHM+SIPI 的分類結果中闊葉樹種的制圖精度和用戶精度最高, 分別為 87.10%和 75.00%, 優于 AISA+CHM(70.97%, 66.67%)以及僅 AISA 的分類結果(41.94%, 61.90%)。 這說明將機載 LiDAR 數據 CHM 與高光譜 AISA 融合, 并添加植被指數 SIPI 能有效區分混合像元并提高分類精度, 對古田山國家級自然保護區進行樹種類型的精細分類具有可行性。 但由于陰影區域的存在、 樹冠間相互遮擋、 少部分邊緣像元的光譜混合等, 對樹種分類的精度有一定影響。 后續擬研究基于高空間分辨率數據的像元解混技術, 希望能有效提高復雜林區的樹種識別精度。